

La plataforma de edición CapCut ha unido fuerzas con Gemini, la inteligencia artificial de Google, para ofrecer a los usuarios la posibilidad de modificar imágenes y videos sin necesidad de cambiar de aplicación. La alianza promete simplificar el flujo creativo al centralizar la edición dentro del entorno conversacional de Gemini.
La integración busca reducir los pasos en el proceso: en lugar de concebir una idea en Gemini, exportar archivos y luego editarlos en otra herramienta, todo ocurre en el mismo espacio. Los ajustes se vuelven más rápidos y se elimina la fricción entre borradores. A medida que los flujos de trabajo creativos se vuelven más conectados, la apuesta apunta a un modelo donde crear, corregir y publicar sea parte de una misma experiencia, más conversacional e intuitiva: el usuario pide cambios, prueba versiones y afina el contenido sin interrupciones.

Funciones: qué se podrá hacer dentro de Gemini
La asociación permite acceder a herramientas avanzadas de edición de CapCut directamente desde Gemini para trabajar sobre imágenes y videos. El objetivo es que la edición deje de ser una etapa separada y se integre al proceso desde el primer borrador, con iteraciones más rápidas y ajustes vinculados a lo que el usuario solicita en la conversación.
Disponibilidad: cuándo llega la integración
Por el momento, el anuncio indicó que la edición dentro de Gemini estará disponible “pronto”, sin una fecha concreta ni un calendario detallado. La integración se presentó como el inicio de una estrategia más amplia: conectar herramientas y experiencias para que la creación ocurra en un entorno único, con funciones integradas de manera inteligente entre plataformas.

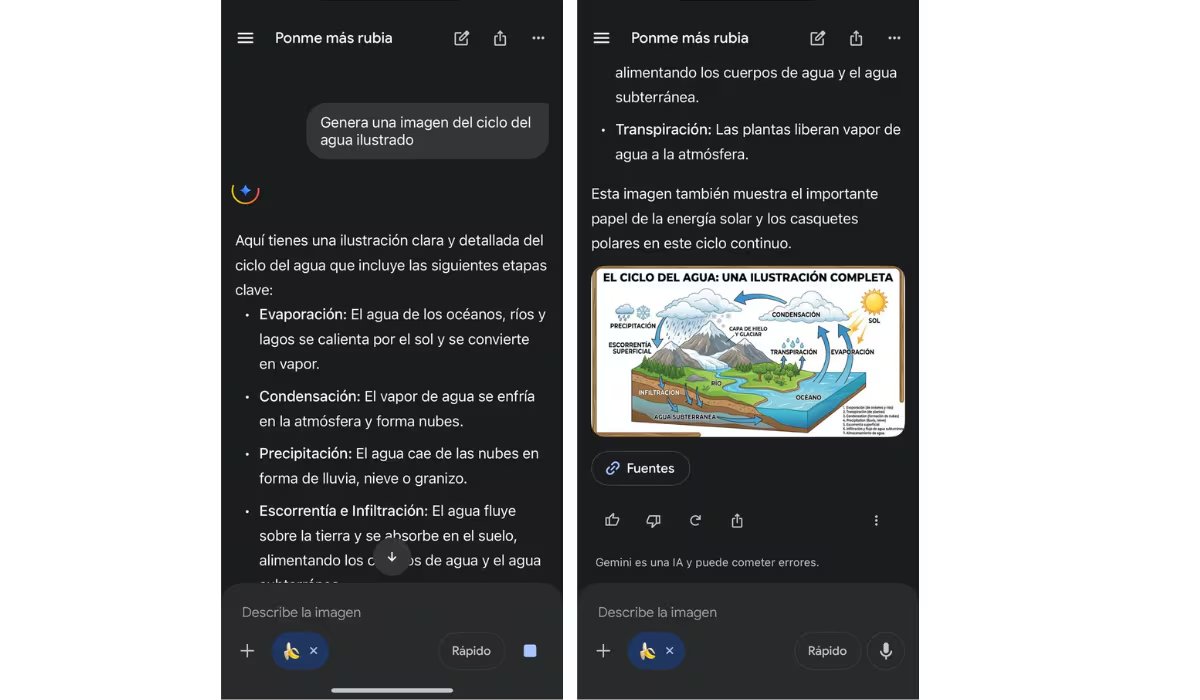
Mientras llega la integración de CapCut, Gemini ya permite realizar algunas ediciones de fotografías con inteligencia artificial. Entre las opciones más habituales figura la posibilidad de modificar elementos de una imagen a partir de una instrucción en lenguaje natural, como ajustar colores o retocar detalles puntuales para probar variantes sin abrir un editor externo.
Por ejemplo, el usuario puede pedir cambios de estilo —como probar un color de pelo distinto— y solicitar ajustes sobre partes específicas de la imagen para comparar resultados y elegir la versión final gracias al modelo de IA Nano Banana. En video, Gemini también ofrece capacidades de creación asistida, orientadas a generar clips a partir de instrucciones y materiales proporcionados por el usuario.
Qué es Nano Banana en Gemini
Nano Banana es un modelo avanzado de generación de imágenes con inteligencia artificial desarrollado por Google e integrado directamente en la plataforma. En sus versiones más recientes —conocidas como Nano Banana 2— permite crear imágenes a partir de descripciones escritas (prompts) y combinar estilos de distintos universos visuales, desde estética de animación hasta referencias de videojuegos populares.

El modelo permite generar imágenes personalizadas a partir de una consigna que describa el personaje, el estilo visual y los detalles de la escena. Por ejemplo, un usuario puede pedir cómo se vería un personaje conocido con una estética similar a la de Fortnite o GTA, y la IA produce una imagen que integra ambos mundos de forma consistente.
Según la información disponible sobre el despliegue del modelo en el ecosistema de Google, Nano Banana está disponible de forma gratuita en Gemini y también puede encontrarse en otras plataformas de la compañía, como el buscador, AI Studio, Google Cloud y Google Ads. El sistema responde con rapidez a las instrucciones y puede apoyarse en conocimiento del mundo real; incluso puede recurrir a imágenes recientes disponibles en la web para construir representaciones más precisas y actuales, de acuerdo con la configuración y disponibilidad de la función.
Entre sus funciones avanzadas, puede generar texto legible dentro de las imágenes —una capacidad útil para maquetas, tarjetas y piezas de diseño—, adaptar ese texto a distintos idiomas y componer elementos visuales con alto nivel de detalle. Además, las imágenes generadas incluyen identificadores y credenciales de contenido orientados a aportar transparencia sobre el origen del material y el proceso de creación mediante inteligencia artificial.
Fuente: Infobae
